Note
Click here to download the full example code
Scalable training of HDP topic models¶
In this demo, we’ll review the scalable memoized training of HDP topic models.
To review, our memoized VB algorithm (Hughes and Sudderth, NeurIPS 2013) proceeds like this pseudocode:
n_laps_completed = 0
while n_laps_completed < nLap:
n_batches_completed_this_lap = 0
while n_batches_completed_this_lap < nBatch:
batch_data = next_minibatch()
# Batch-specific local step
LPbatch = model.calc_local_params(batch_data, **local_step_kwargs)
# Batch-specific summary step
SSbatch = model.get_summary_stats(batch_data, LPbatch)
# Increment global summary statistics
SS = update_global_stats(SS, SSbatch)
# Update global parameters
model.update_global_params(SS)
From a runtime perspective, the important settings a user can control are:
nBatch: the number of batches
nLap : the number of required laps (passes thru full dataset) to perform
local_step_kwargs : dict of keyword arguments that control local step optimization
What happens at each step?¶
In the local step, we visit each document in the current batch. At each document, we estimate its local (document-specific) variational posterior. This is done via an iterative algorithm, which is rather expensive. We might need 50 or 100 or 200 iterations at each document, though each iteration is linear in the number of documents and the number of topics.
The summary step simply computes the sufficient statistics for the batch. Usually this is far faster than the local step, since it a closed-form computation not an iterative estimation.
The global parameter update step is similarly quite fast, because we’re using a model that enjoys conjugacy (e.g. the observation model’s global posterior is a Dirichlet, related to a Multinomial likelihood and a Dirichlet prior).
Thus, the local step is the runtime bottleneck.
Runtime vs nBatch¶
It may be tempting to think that smaller minibatches (increasing nBatch) will make the code go “faster”. However, if you fix the number of laps to be completed, increasing the number of batches leads to strictly more work.
However, for each of the requested laps, here’s the work performed:
the same number of per-document local update iterations are completed
the same number of per-document summaries are completed
the total number of global parameter updates is exactly nBatch
For scaling to large datasets, the important thing is not to keep the number of laps the same, but to keep the wallclock runtime the same, and then to ask how much progress is made in reducing the loss (either training loss or validation loss, whichever is more relevant). Running with larger nBatch values will usually give improved progress in the same amount of time.
Runtime vs Local Step Convergence Thresholds¶
Since the local step dominates the cost of updates, managing the run time of the local iterations is important.
There are two settings in the code that control this:
nCoordAscentItersLP : number of local step iterations to perform per document
convThrLP : threshold to decide if local step updates have converged
The local step pseudocode is:
for each document d:
for iter in [1, 2, ..., nCoordAscentItersLP]:
# Update q(\pi_d), the variational posterior for document d's
# topic probability vector
# Update q(z_d), the variational posterior for document d's
# topic-word discrete assignments
# Compute N_d1, ... N_dK, expected count of topic k in document d
if iter % 5 == 0: # every 5 iterations, check for early convergence
# Quit early if no N_dk entry changes by more than convThrLP
Thus, setting these local step optimization hyperparameters can be very practically important.
Setting convThrLP to -1 (or any number less than zero) will always do all the requested iterations. Setting convThrLP to something moderate (like 0.05) will often reduce the local step cost by 2x or more.
import bnpy
import numpy as np
import os
import matplotlib.pyplot as plt
Read text dataset from file
Keep the first 6400 documents so we have a nice even number
dataset_path = os.path.join(bnpy.DATASET_PATH, 'wiki')
dataset = bnpy.data.BagOfWordsData.LoadFromFile_ldac(
os.path.join(dataset_path, 'train.ldac'),
vocabfile=os.path.join(dataset_path, 'vocab.txt'))
# Keep 6400 documents with at least 50 words
doc_ids = np.flatnonzero(dataset.getDocTypeCountMatrix().sum(axis=1) >= 50)
dataset = dataset.make_subset(docMask=doc_ids[:6400], doTrackFullSize=False)
Train scalable HDP topic models¶
Vary the number of batches and the local step convergence threshold
# Model kwargs
gamma = 25.0
alpha = 0.5
lam = 0.1
# Initialization kwargs
K = 25
# Algorithm kwargs
nLap = 5
traceEvery = 0.5
printEvery = 0.5
convThr = 0.01
for row_id, convThrLP in enumerate([-1.00, 0.25]):
local_step_kwargs = dict(
# perform at most this many iterations at each document
nCoordAscentItersLP=100,
# stop local iters early when max change in doc-topic counts < this thr
convThrLP=convThrLP,
)
for nBatch in [1, 16]:
output_path = '/tmp/wiki/scalability-model=hdp_topic+mult-alg=memoized-nBatch=%d-nCoordAscentItersLP=%s-convThrLP=%.3g/' % (
nBatch, local_step_kwargs['nCoordAscentItersLP'], convThrLP)
trained_model, info_dict = bnpy.run(
dataset, 'HDPTopicModel', 'Mult', 'memoVB',
output_path=output_path,
nLap=nLap, nBatch=nBatch, convThr=convThr,
K=K, gamma=gamma, alpha=alpha, lam=lam,
initname='randomlikewang',
moves='shuffle',
traceEvery=traceEvery, printEvery=printEvery,
**local_step_kwargs)
Dataset Summary:
BagOfWordsData
total size: 6400 units
batch size: 6400 units
num. batches: 1
Allocation Model: HDP model with K=0 active comps. gamma=25.00. alpha=0.50
Obs. Data Model: Multinomial over finite vocabulary.
Obs. Data Prior: Dirichlet over finite vocabulary
lam = [0.1 0.1] ...
Initialization:
initname = randomlikewang
K = 25 (number of clusters)
seed = 1607680
elapsed_time: 0.0 sec
Learn Alg: memoVB | task 1/1 | alg. seed: 1607680 | data order seed: 8541952
task_output_path: /tmp/wiki/scalability-model=hdp_topic+mult-alg=memoized-nBatch=1-nCoordAscentItersLP=100-convThrLP=-1/1
1.000/5 after 21 sec. | 629.3 MiB | K 25 | loss 8.524931808e+00 |
2.000/5 after 41 sec. | 642.8 MiB | K 25 | loss 8.424868135e+00 | Ndiff64262.723
3.000/5 after 62 sec. | 642.8 MiB | K 25 | loss 8.281559226e+00 | Ndiff96336.179
4.000/5 after 82 sec. | 642.8 MiB | K 25 | loss 8.189309395e+00 | Ndiff92668.664
5.000/5 after 103 sec. | 642.8 MiB | K 25 | loss 8.132816746e+00 | Ndiff73088.704
... done. not converged. max laps thru data exceeded.
Dataset Summary:
BagOfWordsData
total size: 6400 units
batch size: 400 units
num. batches: 16
Allocation Model: HDP model with K=0 active comps. gamma=25.00. alpha=0.50
Obs. Data Model: Multinomial over finite vocabulary.
Obs. Data Prior: Dirichlet over finite vocabulary
lam = [0.1 0.1] ...
Initialization:
initname = randomlikewang
K = 25 (number of clusters)
seed = 1607680
elapsed_time: 0.0 sec
Learn Alg: memoVB | task 1/1 | alg. seed: 1607680 | data order seed: 8541952
task_output_path: /tmp/wiki/scalability-model=hdp_topic+mult-alg=memoized-nBatch=16-nCoordAscentItersLP=100-convThrLP=-1/1
0.062/5 after 1 sec. | 337.2 MiB | K 25 | loss 9.531189882e+00 |
0.125/5 after 3 sec. | 359.2 MiB | K 25 | loss 9.006368522e+00 |
0.188/5 after 4 sec. | 339.5 MiB | K 25 | loss 8.806502436e+00 |
0.500/5 after 11 sec. | 359.8 MiB | K 25 | loss 8.467480192e+00 |
1.000/5 after 22 sec. | 383.4 MiB | K 25 | loss 8.320662377e+00 |
1.500/5 after 32 sec. | 383.4 MiB | K 25 | loss 8.248913541e+00 | Ndiff 6033.618
2.000/5 after 43 sec. | 379.6 MiB | K 25 | loss 8.164549711e+00 | Ndiff52349.841
2.500/5 after 54 sec. | 384.2 MiB | K 25 | loss 8.151080023e+00 | Ndiff52349.841
3.000/5 after 65 sec. | 406.7 MiB | K 25 | loss 8.116495124e+00 | Ndiff35271.864
3.500/5 after 76 sec. | 360.5 MiB | K 25 | loss 8.109997041e+00 | Ndiff 3247.260
4.000/5 after 87 sec. | 363.0 MiB | K 25 | loss 8.092532637e+00 | Ndiff58174.730
4.500/5 after 98 sec. | 380.8 MiB | K 25 | loss 8.087635863e+00 | Ndiff 2104.671
5.000/5 after 109 sec. | 403.6 MiB | K 25 | loss 8.077369841e+00 | Ndiff61984.353
... done. not converged. max laps thru data exceeded.
Dataset Summary:
BagOfWordsData
total size: 6400 units
batch size: 6400 units
num. batches: 1
Allocation Model: HDP model with K=0 active comps. gamma=25.00. alpha=0.50
Obs. Data Model: Multinomial over finite vocabulary.
Obs. Data Prior: Dirichlet over finite vocabulary
lam = [0.1 0.1] ...
Initialization:
initname = randomlikewang
K = 25 (number of clusters)
seed = 1607680
elapsed_time: 0.0 sec
Learn Alg: memoVB | task 1/1 | alg. seed: 1607680 | data order seed: 8541952
task_output_path: /tmp/wiki/scalability-model=hdp_topic+mult-alg=memoized-nBatch=1-nCoordAscentItersLP=100-convThrLP=0.25/1
1.000/5 after 13 sec. | 680.6 MiB | K 25 | loss 8.532773413e+00 |
2.000/5 after 24 sec. | 693.8 MiB | K 25 | loss 8.433359333e+00 | Ndiff59669.458
3.000/5 after 34 sec. | 693.8 MiB | K 25 | loss 8.289494765e+00 | Ndiff65081.816
4.000/5 after 43 sec. | 693.8 MiB | K 25 | loss 8.197018858e+00 | Ndiff77516.592
5.000/5 after 51 sec. | 693.8 MiB | K 25 | loss 8.140545185e+00 | Ndiff73205.620
... done. not converged. max laps thru data exceeded.
Dataset Summary:
BagOfWordsData
total size: 6400 units
batch size: 400 units
num. batches: 16
Allocation Model: HDP model with K=0 active comps. gamma=25.00. alpha=0.50
Obs. Data Model: Multinomial over finite vocabulary.
Obs. Data Prior: Dirichlet over finite vocabulary
lam = [0.1 0.1] ...
Initialization:
initname = randomlikewang
K = 25 (number of clusters)
seed = 1607680
elapsed_time: 0.0 sec
Learn Alg: memoVB | task 1/1 | alg. seed: 1607680 | data order seed: 8541952
task_output_path: /tmp/wiki/scalability-model=hdp_topic+mult-alg=memoized-nBatch=16-nCoordAscentItersLP=100-convThrLP=0.25/1
0.062/5 after 1 sec. | 362.3 MiB | K 25 | loss 9.545032888e+00 |
0.125/5 after 1 sec. | 370.9 MiB | K 25 | loss 9.017962537e+00 |
0.188/5 after 2 sec. | 370.9 MiB | K 25 | loss 8.817299651e+00 |
0.500/5 after 5 sec. | 371.9 MiB | K 25 | loss 8.476303437e+00 |
1.000/5 after 9 sec. | 411.0 MiB | K 25 | loss 8.328292116e+00 |
1.500/5 after 13 sec. | 391.5 MiB | K 25 | loss 8.255930038e+00 | Ndiff 5696.282
2.000/5 after 17 sec. | 414.0 MiB | K 25 | loss 8.171153832e+00 | Ndiff60840.642
2.500/5 after 21 sec. | 368.2 MiB | K 25 | loss 8.157750198e+00 | Ndiff60840.642
3.000/5 after 25 sec. | 411.6 MiB | K 25 | loss 8.123241075e+00 | Ndiff56677.641
3.500/5 after 29 sec. | 413.5 MiB | K 25 | loss 8.116762516e+00 | Ndiff 3222.854
4.000/5 after 33 sec. | 411.8 MiB | K 25 | loss 8.098976267e+00 | Ndiff49797.809
4.500/5 after 36 sec. | 391.5 MiB | K 25 | loss 8.093910662e+00 | Ndiff 2099.082
5.000/5 after 40 sec. | 411.8 MiB | K 25 | loss 8.083408441e+00 | Ndiff34527.081
... done. not converged. max laps thru data exceeded.
Plot: Training Loss and Laps Completed vs. Wallclock time¶
Left column: Training Loss progress vs. wallclock time
Right column: Laps completed vs. wallclock time
Remember: one lap is a complete pass through entire training set (6400 docs)
H = 3; W = 4
fig, ax = plt.subplots(nrows=2, ncols=2, figsize=(2*W,2*H), sharex=True, sharey=False)
for row_id, convThrLP in enumerate([-1.00, 0.25]):
for nBatch in [1, 16]:
output_path = '/tmp/wiki/scalability-model=hdp_topic+mult-alg=memoized-nBatch=%d-nCoordAscentItersLP=%s-convThrLP=%.3g/' % (
nBatch, local_step_kwargs['nCoordAscentItersLP'], convThrLP)
elapsed_time_T = np.loadtxt(os.path.join(output_path, '1', 'trace_elapsed_time_sec.txt'))
elapsed_laps_T = np.loadtxt(os.path.join(output_path, '1', 'trace_lap.txt'))
loss_T = np.loadtxt(os.path.join(output_path, '1', 'trace_loss.txt'))
ax[row_id, 0].plot(elapsed_time_T, loss_T, '.-', label='nBatch=%d, batch_size = %d' % (nBatch, 6400/nBatch))
ax[row_id, 1].plot(elapsed_time_T, elapsed_laps_T, '.-', label='nBatch=%d' % nBatch)
ax[row_id, 0].set_ylabel('training loss')
ax[row_id, 1].set_ylabel('laps completed')
ax[row_id, 0].set_xlabel('elapsed time (sec)')
ax[row_id, 1].set_xlabel('elapsed time (sec)')
ax[row_id, 0].legend(loc='upper right')
ax[row_id, 0].set_title(('Loss vs Time, local conv. thr. %.2f' % (convThrLP)).replace(".00", ""))
ax[row_id, 1].set_title(('Laps vs Time, local conv. thr. %.2f' % (convThrLP)).replace(".00", ""))
plt.tight_layout()
plt.show()
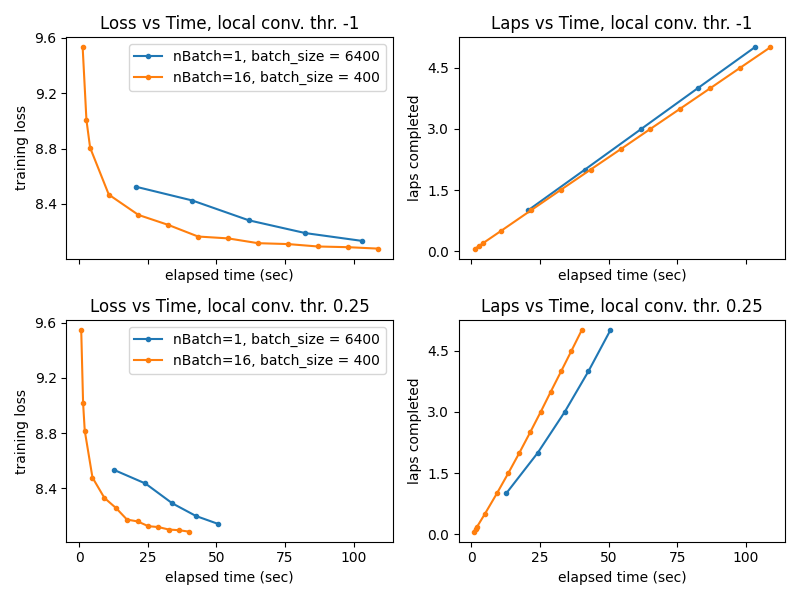
Lessons Learned¶
The local step is the most expensive step in terms of runtime (far more costly than the summary or global step) Generally, increasing the number of batches has the following effect: * Increase the total computational work that must be done for a fixed number of laps * Improve the model quality achieved in a limited amount of time, unless the batch size becomes so small that global parameter estimates are poor
We generally recommend considering: * batch size around 250 - 2000 (which means set nBatch = nDocsTotal / batch_size) * carefully setting the local step convergence threshold (convThrLP could be 0.05 or 0.25 when training, probably needs to be smaller when computing likelihoods for a document) * setting the number of iterations per document sufficiently large (might get away with nCoordAscentItersLP = 10 or 25 when training, but might need many iters like 50 or 100 at least when evaluating likelihoods to be confident in the value)
Total running time of the script: ( 5 minutes 4.281 seconds)