Note
Click here to download the full example code
Warm Starting from a Previously Trained Mixture of Gaussians¶
Here, we show how to “warm start” from an existing model.
This may be useful for several situations, such as:
An “online” setting, where you have gained some additional data, and wish to apply a previous model without starting from scratch.
You wish to take a previous run which might not have converged and train for several more laps (aka epochs or passes thru full data).
You wish to try a slightly different model (alternative prior hyperparameters, etc.) or a slightly different algorithm, and see if the previously discovered solution is still preferred.
The existing model should be saved on disk, in BNPy format.
Any previous call to bnpy.run that specifies a valid output_path will produce a file of the required format.
The key idea to warm starting with BNPy is that you can specify the full path of the desired previous training run as the “initname” keyword argument when you call bnpy.run:
bnpy.run(…, initname=’/path/to/previous_training_output/’, …)
# SPECIFY WHICH PLOT CREATED BY THIS SCRIPT IS THE THUMBNAIL IMAGE
# sphinx_gallery_thumbnail_number = 4
import bnpy
import numpy as np
import os
from matplotlib import pylab
import seaborn as sns
FIG_SIZE = (3, 3)
pylab.rcParams['figure.figsize'] = FIG_SIZE
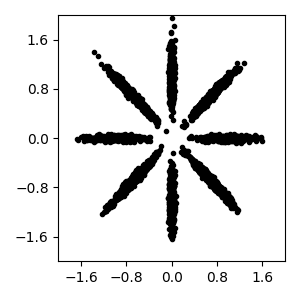
Read bnpy’s built-in “AsteriskK8” dataset from file.
5000 examples, each one a 2D point
dataset_path = os.path.join(bnpy.DATASET_PATH, 'AsteriskK8')
dataset = bnpy.data.XData.read_npz(
os.path.join(dataset_path, 'x_dataset.npz'))
Make a simple plot of the raw data
pylab.figure()
pylab.plot(dataset.X[:, 0], dataset.X[:, 1], 'k.')
pylab.gca().set_xlim([-2, 2])
pylab.gca().set_ylim([-2, 2])
pylab.tight_layout()
Cold-start model training¶
Let’s do one single run of the VB algorithm.
Using 10 clusters and the ‘randexamples’ initialization procedure.
cold_start_model, cold_info_dict = bnpy.run(
dataset, 'FiniteMixtureModel', 'Gauss', 'VB',
output_path='/tmp/AsteriskK8/coldstart-K=10/',
nLap=25,
sF=0.1, ECovMat='eye',
K=10,
initname='randexamples')
Dataset Summary:
X Data
num examples: 5000
num dims: 2
Allocation Model: Finite mixture model. Dir prior param 1.00
Obs. Data Model: Gaussian with full covariance.
Obs. Data Prior: Gauss-Wishart on mean and covar of each cluster
E[ mean[k] ] =
[0. 0.]
E[ covar[k] ] =
[[0.1 0. ]
[0. 0.1]]
Initialization:
initname = randexamples
K = 10 (number of clusters)
seed = 1607680
elapsed_time: 0.0 sec
Learn Alg: VB | task 1/1 | alg. seed: 1607680 | data order seed: 8541952
task_output_path: /tmp/AsteriskK8/coldstart-K=10/1
1/25 after 0 sec. | 204.1 MiB | K 10 | loss 6.582634775e-01 |
2/25 after 0 sec. | 204.1 MiB | K 10 | loss 4.350235353e-01 | Ndiff 68.926
3/25 after 0 sec. | 204.1 MiB | K 10 | loss 3.454096950e-01 | Ndiff 193.565
4/25 after 0 sec. | 204.1 MiB | K 10 | loss 3.049230819e-01 | Ndiff 175.237
5/25 after 0 sec. | 204.1 MiB | K 10 | loss 2.732439109e-01 | Ndiff 108.630
6/25 after 0 sec. | 204.1 MiB | K 10 | loss 2.326372999e-01 | Ndiff 42.961
7/25 after 0 sec. | 204.1 MiB | K 10 | loss 2.100254570e-01 | Ndiff 9.814
8/25 after 0 sec. | 204.1 MiB | K 10 | loss 2.097453779e-01 | Ndiff 10.216
9/25 after 0 sec. | 204.1 MiB | K 10 | loss 2.094741199e-01 | Ndiff 10.608
10/25 after 0 sec. | 204.1 MiB | K 10 | loss 2.091535256e-01 | Ndiff 11.009
11/25 after 0 sec. | 204.1 MiB | K 10 | loss 2.087740779e-01 | Ndiff 11.403
12/25 after 0 sec. | 204.1 MiB | K 10 | loss 2.083262051e-01 | Ndiff 11.781
13/25 after 0 sec. | 204.1 MiB | K 10 | loss 2.078022512e-01 | Ndiff 12.135
14/25 after 0 sec. | 204.1 MiB | K 10 | loss 2.072001819e-01 | Ndiff 12.449
15/25 after 0 sec. | 204.1 MiB | K 10 | loss 2.065288318e-01 | Ndiff 12.706
16/25 after 0 sec. | 204.1 MiB | K 10 | loss 2.058118708e-01 | Ndiff 12.883
17/25 after 1 sec. | 204.1 MiB | K 10 | loss 2.050844132e-01 | Ndiff 12.951
18/25 after 1 sec. | 204.1 MiB | K 10 | loss 2.043795824e-01 | Ndiff 12.873
19/25 after 1 sec. | 204.1 MiB | K 10 | loss 2.037146182e-01 | Ndiff 12.598
20/25 after 1 sec. | 204.1 MiB | K 10 | loss 2.030678434e-01 | Ndiff 12.069
21/25 after 1 sec. | 204.1 MiB | K 10 | loss 2.022621299e-01 | Ndiff 11.232
22/25 after 1 sec. | 204.1 MiB | K 10 | loss 2.008648784e-01 | Ndiff 10.057
23/25 after 1 sec. | 204.1 MiB | K 10 | loss 2.002168334e-01 | Ndiff 8.536
24/25 after 1 sec. | 204.1 MiB | K 10 | loss 1.995420809e-01 | Ndiff 8.587
25/25 after 1 sec. | 204.1 MiB | K 10 | loss 1.988594991e-01 | Ndiff 9.312
... done. not converged. max laps thru data exceeded.
Setup helper method to visualize clusters¶
Here’s a short function to show how clusters evolve during training.
def show_clusters_over_time(
task_output_path=None,
query_laps=[0, 1, 2, 5, 10, None],
nrows=2):
''' Read model snapshots from provided folder and make visualizations
Post Condition
--------------
New matplotlib plot with some nice pictures.
'''
ncols = int(np.ceil(len(query_laps) // float(nrows)))
fig_handle, ax_handle_list = pylab.subplots(
figsize=(FIG_SIZE[0] * ncols, FIG_SIZE[1] * nrows),
nrows=nrows, ncols=ncols, sharex=True, sharey=True)
for plot_id, lap_val in enumerate(query_laps):
cur_model, lap_val = bnpy.load_model_at_lap(task_output_path, lap_val)
# Plot the current model
cur_ax_handle = ax_handle_list.flatten()[plot_id]
bnpy.viz.PlotComps.plotCompsFromHModel(
cur_model, Data=dataset, ax_handle=cur_ax_handle)
cur_ax_handle.set_xticks([-2, -1, 0, 1, 2])
cur_ax_handle.set_yticks([-2, -1, 0, 1, 2])
cur_ax_handle.set_xlabel("lap: %d" % lap_val)
cur_ax_handle.set_xlim([-2, 2])
cur_ax_handle.set_ylim([-2, 2])
pylab.tight_layout()
Visualize cold start¶
Show the estimated clusters throughout training from cold
show_clusters_over_time(cold_info_dict['task_output_path'])
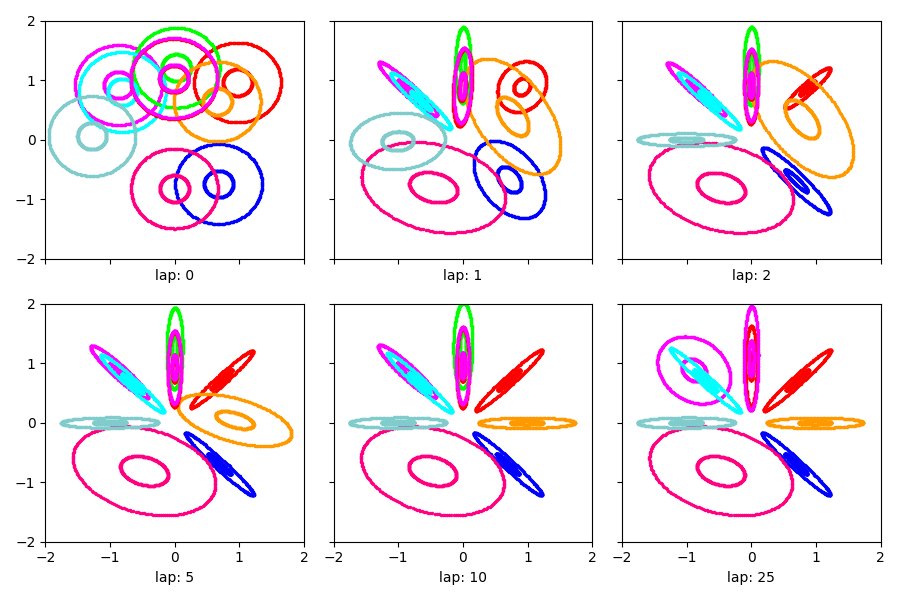
SKIPPED 1 comps with size below 0.00
Warm-start model training¶
Let’s now do a warm-started single run of the VB algorithm.
We’ll apply the same data and the same prior hyperparameters.
Using the previous cold-start training’s final model, as saved in its task_output_path.
Remember that the cold-start training saves its final model in directory specified by cold_info_dict[‘task_output_path’]
warm_start_model, warm_info_dict = bnpy.run(
dataset, 'FiniteMixtureModel', 'Gauss', 'VB',
output_path='/tmp/AsteriskK8/warmstart-K=10/',
nLap=100,
sF=0.1, ECovMat='eye',
initname=cold_info_dict['task_output_path'])
Dataset Summary:
X Data
num examples: 5000
num dims: 2
Allocation Model: Finite mixture model. Dir prior param 1.00
Obs. Data Model: Gaussian with full covariance.
Obs. Data Prior: Gauss-Wishart on mean and covar of each cluster
E[ mean[k] ] =
[0. 0.]
E[ covar[k] ] =
[[0.1 0. ]
[0. 0.1]]
Initialization:
initname = /tmp/AsteriskK8/coldstart-K=10/1
K = 6 (number of clusters)
seed = 1607680
elapsed_time: 0.0 sec
Learn Alg: VB | task 1/1 | alg. seed: 1607680 | data order seed: 8541952
task_output_path: /tmp/AsteriskK8/warmstart-K=10/1
1/100 after 0 sec. | 205.9 MiB | K 10 | loss 1.982035545e-01 |
2/100 after 0 sec. | 205.9 MiB | K 10 | loss 1.974254707e-01 | Ndiff 10.598
3/100 after 0 sec. | 205.9 MiB | K 10 | loss 1.966834121e-01 | Ndiff 11.131
4/100 after 0 sec. | 205.9 MiB | K 10 | loss 1.964267444e-01 | Ndiff 11.549
5/100 after 0 sec. | 205.9 MiB | K 10 | loss 1.961250819e-01 | Ndiff 11.802
6/100 after 0 sec. | 205.9 MiB | K 10 | loss 1.957730227e-01 | Ndiff 11.830
7/100 after 0 sec. | 205.9 MiB | K 10 | loss 1.953666781e-01 | Ndiff 11.565
8/100 after 0 sec. | 205.9 MiB | K 10 | loss 1.949058031e-01 | Ndiff 10.930
9/100 after 0 sec. | 205.9 MiB | K 10 | loss 1.943977009e-01 | Ndiff 9.860
10/100 after 0 sec. | 205.9 MiB | K 10 | loss 1.938623040e-01 | Ndiff 8.334
11/100 after 0 sec. | 205.9 MiB | K 10 | loss 1.933345511e-01 | Ndiff 6.449
12/100 after 0 sec. | 205.9 MiB | K 10 | loss 1.928570776e-01 | Ndiff 4.458
13/100 after 0 sec. | 205.9 MiB | K 10 | loss 1.924667495e-01 | Ndiff 2.727
14/100 after 0 sec. | 205.9 MiB | K 10 | loss 1.921899371e-01 | Ndiff 1.530
15/100 after 0 sec. | 205.9 MiB | K 10 | loss 1.919922352e-01 | Ndiff 0.873
16/100 after 0 sec. | 205.9 MiB | K 10 | loss 1.916267958e-01 | Ndiff 0.492
17/100 after 0 sec. | 205.9 MiB | K 10 | loss 1.909787395e-01 | Ndiff 0.045
... done. converged.
Visualize warm start¶
Show the estimated clusters throughout training from warm
We’ll see that not much changes (since the init was already pretty good)
show_clusters_over_time(warm_info_dict['task_output_path'])
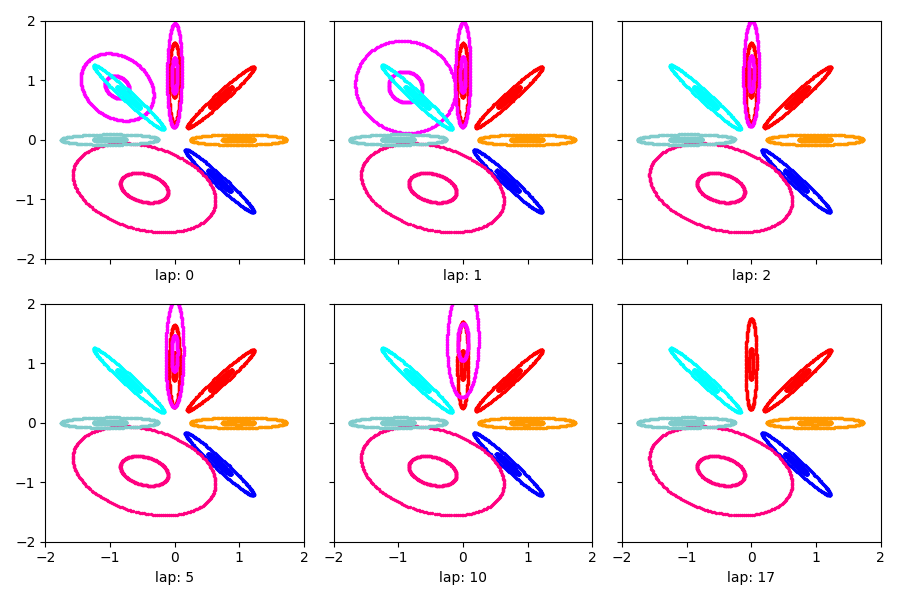
SKIPPED 1 comps with size below 0.00
SKIPPED 1 comps with size below 0.00
SKIPPED 2 comps with size below 0.00
SKIPPED 2 comps with size below 0.00
SKIPPED 2 comps with size below 0.00
SKIPPED 3 comps with size below 0.00
Warm-start with different algorithm¶
We can apply a different algorithm to the same warm initialization.
Here, we’ll do stochastic VB (soVB) which divides the data into 100 batches at random (each ~50 examples) and processes one batch at a time with learning rate rho that decays with step t as:
rho(t) <- (1 + t)^(-0.55)
warm_stoch_model, warm_stoch_info_dict = bnpy.run(
dataset, 'FiniteMixtureModel', 'Gauss', 'soVB',
output_path='/tmp/AsteriskK8/warmstart-K=10-alg=soVB/',
nLap=5, nTask=1, nBatch=500,
rhoexp=0.55, rhodelay=1,
sF=0.1, ECovMat='eye',
initname=cold_info_dict['task_output_path'],
)
Dataset Summary:
X Data
total size: 5000 units
batch size: 10 units
num. batches: 500
Allocation Model: Finite mixture model. Dir prior param 1.00
Obs. Data Model: Gaussian with full covariance.
Obs. Data Prior: Gauss-Wishart on mean and covar of each cluster
E[ mean[k] ] =
[0. 0.]
E[ covar[k] ] =
[[0.1 0. ]
[0. 0.1]]
Initialization:
initname = /tmp/AsteriskK8/coldstart-K=10/1
K = 6 (number of clusters)
seed = 1607680
elapsed_time: 0.0 sec
Learn Alg: soVB | task 1/1 | alg. seed: 1607680 | data order seed: 8541952
task_output_path: /tmp/AsteriskK8/warmstart-K=10-alg=soVB/1
0.002/5 after 0 sec. | 207.9 MiB | K 10 | loss 3.858767609e+01 | lrate 0.6830
0.004/5 after 0 sec. | 207.9 MiB | K 10 | loss 2.242266228e+01 | lrate 0.5465
0.006/5 after 0 sec. | 207.9 MiB | K 10 | loss 1.622381779e+01 | lrate 0.4665
1.000/5 after 4 sec. | 207.9 MiB | K 10 | loss 1.109950213e+01 | lrate 0.0327
2.000/5 after 7 sec. | 207.9 MiB | K 10 | loss 1.987460885e-01 | lrate 0.0224
3.000/5 after 11 sec. | 207.9 MiB | K 10 | loss 2.007048846e-01 | lrate 0.0179
4.000/5 after 15 sec. | 207.9 MiB | K 10 | loss 1.954946047e-01 | lrate 0.0153
5.000/5 after 18 sec. | 207.9 MiB | K 10 | loss 1.958695470e-01 | lrate 0.0135
... active. not converged.
Visualize stochastic VB from a warm start¶
Show the estimated clusters throughout training from warm
show_clusters_over_time(warm_stoch_info_dict['task_output_path'])
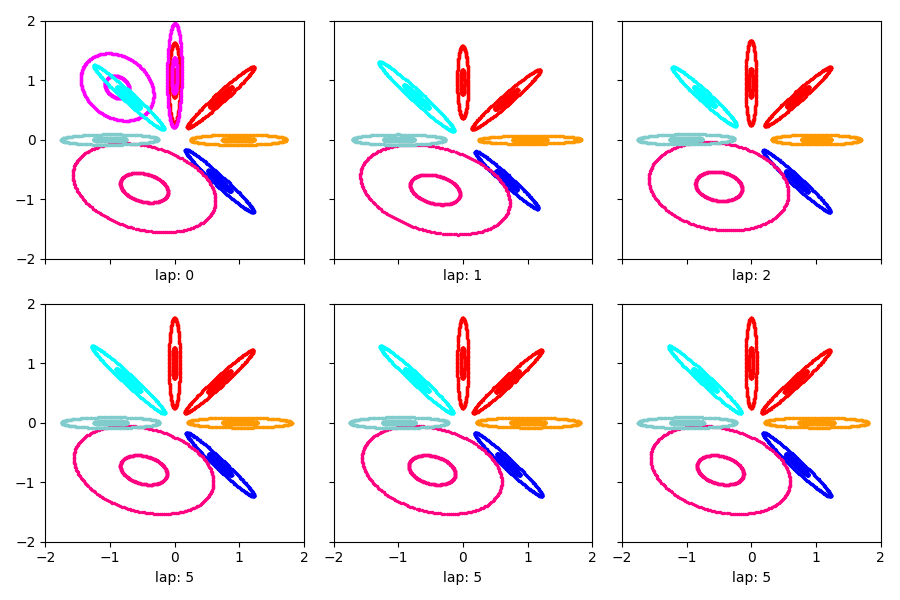
SKIPPED 1 comps with size below 0.00
SKIPPED 3 comps with size below 0.00
SKIPPED 3 comps with size below 0.00
SKIPPED 3 comps with size below 0.00
SKIPPED 3 comps with size below 0.00
SKIPPED 3 comps with size below 0.00
Warm-start with different model: DP mixture model¶
We can apply a different model to the same warm initialization.
Here, we’ll apply a Dirichlet Process (DP) mixture model and use the memoized VB algorithm with birth and merge proposals.
warm_proposals_model, warm_proposals_info_dict = bnpy.run(
dataset, 'DPMixtureModel', 'Gauss', 'memoVB',
output_path='/tmp/AsteriskK8/warmstart-dp_mix-alg=memo_birth_merge/',
nLap=100, nTask=1, nBatch=1,
sF=0.1, ECovMat='eye',
initname=cold_info_dict['task_output_path'],
moves='birth,merge,shuffle',
m_startLap=5, b_startLap=2, b_Kfresh=4)
Dataset Summary:
X Data
total size: 5000 units
batch size: 5000 units
num. batches: 1
Allocation Model: DP mixture with K=0. Concentration gamma0= 1.00
Obs. Data Model: Gaussian with full covariance.
Obs. Data Prior: Gauss-Wishart on mean and covar of each cluster
E[ mean[k] ] =
[0. 0.]
E[ covar[k] ] =
[[0.1 0. ]
[0. 0.1]]
Initialization:
initname = /tmp/AsteriskK8/coldstart-K=10/1
K = 6 (number of clusters)
seed = 1607680
elapsed_time: 0.0 sec
Learn Alg: memoVB | task 1/1 | alg. seed: 1607680 | data order seed: 8541952
task_output_path: /tmp/AsteriskK8/warmstart-dp_mix-alg=memo_birth_merge/1
BIRTH @ lap 1.00: Disabled. Waiting for lap >= 2 (--b_startLap).
MERGE @ lap 1.00: Disabled. Cannot plan merge on first lap. Need valid SS that represent whole dataset.
1.000/100 after 0 sec. | 205.9 MiB | K 10 | loss 1.965595456e-01 |
MERGE @ lap 2.00: Disabled. Waiting for lap >= 5 (--m_startLap).
BIRTH @ lap 2.00 : Added 4 states. 1/8 succeeded. 7/8 failed eval phase. 0/8 failed build phase.
2.000/100 after 1 sec. | 205.9 MiB | K 14 | loss -4.287337941e-03 |
MERGE @ lap 3.00: Disabled. Waiting for lap >= 5 (--m_startLap).
BIRTH @ lap 3.00 : Added 0 states. 0/6 succeeded. 5/6 failed eval phase. 1/6 failed build phase.
3.000/100 after 2 sec. | 205.9 MiB | K 14 | loss -2.714086945e-02 | Ndiff 44.963
MERGE @ lap 4.00: Disabled. Waiting for lap >= 5 (--m_startLap).
BIRTH @ lap 4.00 : Added 0 states. 0/6 succeeded. 5/6 failed eval phase. 1/6 failed build phase.
4.000/100 after 2 sec. | 205.9 MiB | K 14 | loss -2.825422926e-02 | Ndiff 12.358
BIRTH @ lap 5.000 : None attempted. 0 past failures. 0 too small. 14 too busy.
MERGE @ lap 5.00 : 4/24 accepted. Ndiff 201.07. 7 skipped.
5.000/100 after 3 sec. | 205.9 MiB | K 10 | loss -3.979560426e-02 | Ndiff 12.358
BIRTH @ lap 6.000 : None attempted. 1 past failures. 0 too small. 9 too busy.
MERGE @ lap 6.00 : 2/15 accepted. Ndiff 269.36. 5 skipped.
6.000/100 after 3 sec. | 205.9 MiB | K 8 | loss -4.787959362e-02 | Ndiff 12.358
BIRTH @ lap 7.000 : None attempted. 0 past failures. 0 too small. 8 too busy.
MERGE @ lap 7.00 : 0/8 accepted. Ndiff 0.00. 0 skipped.
7.000/100 after 3 sec. | 205.9 MiB | K 8 | loss -4.787962433e-02 | Ndiff 0.001
BIRTH @ lap 8.00 : Added 0 states. 0/1 succeeded. 1/1 failed eval phase. 0/1 failed build phase.
MERGE @ lap 8.00 : 0/2 accepted. Ndiff 0.00. 0 skipped.
8.000/100 after 3 sec. | 205.9 MiB | K 8 | loss -4.787962433e-02 | Ndiff 0.000
MERGE @ lap 9.00: No promising candidates, so no attempts.
BIRTH @ lap 9.00 : Added 0 states. 0/2 succeeded. 2/2 failed eval phase. 0/2 failed build phase.
9.000/100 after 4 sec. | 205.9 MiB | K 8 | loss -4.787962433e-02 | Ndiff 0.000
BIRTH @ lap 10.000 : None attempted. 3 past failures. 0 too small. 5 too busy.
MERGE @ lap 10.00 : 0/10 accepted. Ndiff 0.00. 0 skipped.
10.000/100 after 4 sec. | 205.9 MiB | K 8 | loss -4.787962433e-02 | Ndiff 0.000
BIRTH @ lap 11.000 : None attempted. 2 past failures. 0 too small. 6 too busy.
MERGE @ lap 11.00 : 0/8 accepted. Ndiff 0.00. 0 skipped.
11.000/100 after 4 sec. | 205.9 MiB | K 8 | loss -4.787962433e-02 | Ndiff 0.000
BIRTH @ lap 12.000 : None attempted. 0 past failures. 0 too small. 8 too busy.
MERGE @ lap 12.00 : 0/8 accepted. Ndiff 0.00. 0 skipped.
12.000/100 after 4 sec. | 205.9 MiB | K 8 | loss -4.787962433e-02 | Ndiff 0.000
BIRTH @ lap 13.000 : None attempted. 5 past failures. 0 too small. 3 too busy.
MERGE @ lap 13.00 : 0/2 accepted. Ndiff 0.00. 0 skipped.
13.000/100 after 4 sec. | 205.9 MiB | K 8 | loss -4.787962433e-02 | Ndiff 0.000
MERGE @ lap 14.00: No promising candidates, so no attempts.
BIRTH @ lap 14.000 : None attempted. 8 past failures. 0 too small. 0 too busy.
14.000/100 after 4 sec. | 205.9 MiB | K 8 | loss -4.787962433e-02 | Ndiff 0.000
BIRTH @ lap 15.000 : None attempted. 3 past failures. 0 too small. 5 too busy.
MERGE @ lap 15.00 : 0/10 accepted. Ndiff 0.00. 0 skipped.
15.000/100 after 4 sec. | 205.9 MiB | K 8 | loss -4.787962433e-02 | Ndiff 0.000
BIRTH @ lap 16.000 : None attempted. 2 past failures. 0 too small. 6 too busy.
MERGE @ lap 16.00 : 0/8 accepted. Ndiff 0.00. 0 skipped.
16.000/100 after 5 sec. | 205.9 MiB | K 8 | loss -4.787962433e-02 | Ndiff 0.000
BIRTH @ lap 17.000 : None attempted. 0 past failures. 0 too small. 8 too busy.
MERGE @ lap 17.00 : 0/8 accepted. Ndiff 0.00. 0 skipped.
17.000/100 after 5 sec. | 205.9 MiB | K 8 | loss -4.787962433e-02 | Ndiff 0.000
... done. converged.
Visualize warm start with proposals¶
show_clusters_over_time(warm_proposals_info_dict['task_output_path'])
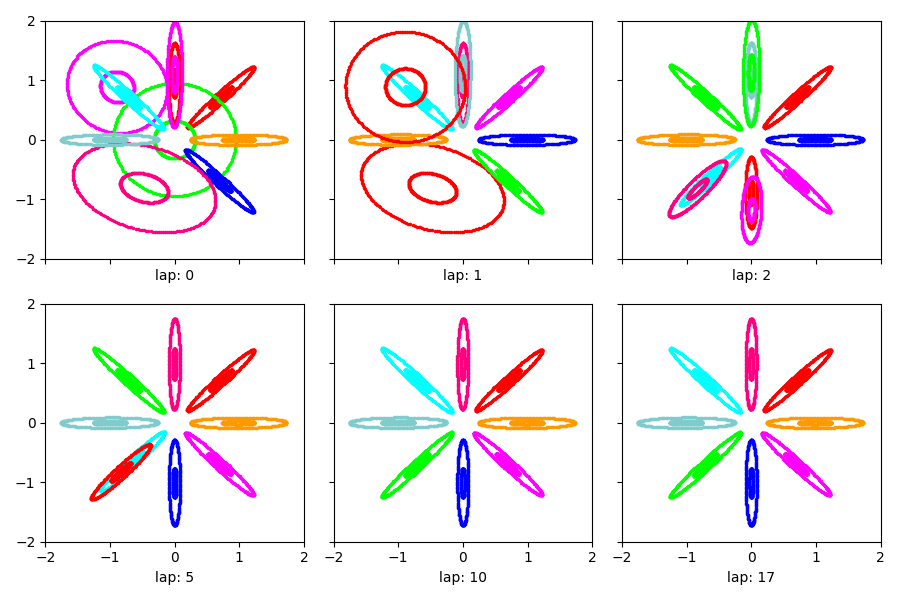
SKIPPED 1 comps with size below 0.00
SKIPPED 3 comps with size below 0.00
SKIPPED 1 comps with size below 0.00
Incorporating additional data¶
Suppose we were to observe a few new examples (shown in red) in addition to the original data
rng = np.random.RandomState(0)
new_x = rng.multivariate_normal(
[1.0, 1.0],
0.2 * np.eye(2),
size=100)
combined_dataset = bnpy.data.XData(np.vstack([dataset.X, new_x]))
pylab.figure()
pylab.plot(combined_dataset.X[:, 0], combined_dataset.X[:, 1], 'r.')
pylab.plot(dataset.X[:, 0], dataset.X[:, 1], 'k.')
pylab.gca().set_xlim([-2, 2])
pylab.gca().set_ylim([-2, 2])
pylab.tight_layout()
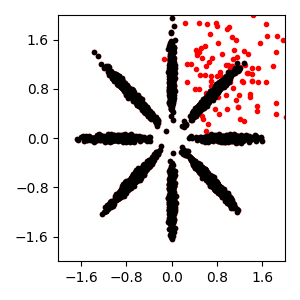
Warm-start with additional data¶
We can initialize from previous “warm started” DP mixture model and apply this model to our expanded dataset. We should see that it discovers an additional cluster of red examples in the upper right quadrant.
extra_data_proposals_model, extra_data_proposals_info_dict = bnpy.run(
combined_dataset, 'DPMixtureModel', 'Gauss', 'memoVB',
output_path='/tmp/AsteriskK8_with_extra/warmstart-dp_mix-alg=memo_birth_merge/',
nLap=100, nTask=1, nBatch=1,
sF=0.1, ECovMat='eye',
initname=warm_proposals_info_dict['task_output_path'],
moves='birth,merge,shuffle',
m_startLap=5, b_startLap=0, b_Kfresh=4)
Dataset Summary:
X Data
total size: 5100 units
batch size: 5100 units
num. batches: 1
Allocation Model: DP mixture with K=0. Concentration gamma0= 1.00
Obs. Data Model: Gaussian with full covariance.
Obs. Data Prior: Gauss-Wishart on mean and covar of each cluster
E[ mean[k] ] =
[0. 0.]
E[ covar[k] ] =
[[0.1 0. ]
[0. 0.1]]
Initialization:
initname = /tmp/AsteriskK8/warmstart-dp_mix-alg=memo_birth_merge/1
K = 6 (number of clusters)
seed = 1607680
elapsed_time: 0.0 sec
Learn Alg: memoVB | task 1/1 | alg. seed: 1607680 | data order seed: 8541952
task_output_path: /tmp/AsteriskK8_with_extra/warmstart-dp_mix-alg=memo_birth_merge/1
MERGE @ lap 1.00: Disabled. Cannot plan merge on first lap. Need valid SS that represent whole dataset.
BIRTH @ lap 1.00 : Added 12 states. 3/8 succeeded. 5/8 failed eval phase. 0/8 failed build phase.
1.000/100 after 1 sec. | 208.1 MiB | K 20 | loss 6.188952141e-02 |
MERGE @ lap 2.00: Disabled. Waiting for lap >= 5 (--m_startLap).
BIRTH @ lap 2.00 : Added 0 states. 0/12 succeeded. 5/12 failed eval phase. 7/12 failed build phase.
2.000/100 after 2 sec. | 208.1 MiB | K 20 | loss 5.493794397e-02 | Ndiff 15.359
MERGE @ lap 3.00: Disabled. Waiting for lap >= 5 (--m_startLap).
BIRTH @ lap 3.00 : Added 0 states. 0/10 succeeded. 4/10 failed eval phase. 6/10 failed build phase.
3.000/100 after 3 sec. | 208.1 MiB | K 20 | loss 5.282671201e-02 | Ndiff 7.714
MERGE @ lap 4.00: Disabled. Waiting for lap >= 5 (--m_startLap).
BIRTH @ lap 4.00 : Added 0 states. 0/10 succeeded. 5/10 failed eval phase. 5/10 failed build phase.
4.000/100 after 4 sec. | 208.1 MiB | K 20 | loss 5.194735563e-02 | Ndiff 5.792
BIRTH @ lap 5.000 : None attempted. 0 past failures. 0 too small. 20 too busy.
MERGE @ lap 5.00 : 6/35 accepted. Ndiff 419.39. 12 skipped.
5.000/100 after 4 sec. | 208.1 MiB | K 14 | loss 3.509372470e-02 | Ndiff 5.792
BIRTH @ lap 6.000 : None attempted. 0 past failures. 0 too small. 14 too busy.
MERGE @ lap 6.00 : 1/29 accepted. Ndiff 4.78. 2 skipped.
6.000/100 after 5 sec. | 208.1 MiB | K 13 | loss 3.175746261e-02 | Ndiff 5.792
BIRTH @ lap 7.000 : None attempted. 0 past failures. 0 too small. 13 too busy.
MERGE @ lap 7.00 : 4/10 accepted. Ndiff 576.80. 14 skipped.
7.000/100 after 5 sec. | 208.1 MiB | K 9 | loss 1.224185972e-02 | Ndiff 5.792
BIRTH @ lap 8.000 : None attempted. 0 past failures. 0 too small. 9 too busy.
MERGE @ lap 8.00 : 0/14 accepted. Ndiff 0.00. 0 skipped.
8.000/100 after 5 sec. | 208.1 MiB | K 9 | loss 1.176655752e-02 | Ndiff 0.977
BIRTH @ lap 9.000 : None attempted. 4 past failures. 0 too small. 5 too busy.
MERGE @ lap 9.00 : 0/6 accepted. Ndiff 0.00. 0 skipped.
9.000/100 after 6 sec. | 208.1 MiB | K 9 | loss 1.175688328e-02 | Ndiff 0.458
BIRTH @ lap 10.00 : Added 0 states. 0/3 succeeded. 3/3 failed eval phase. 0/3 failed build phase.
MERGE @ lap 10.00 : 0/14 accepted. Ndiff 0.00. 0 skipped.
10.000/100 after 6 sec. | 208.1 MiB | K 9 | loss 1.175623885e-02 | Ndiff 0.159
BIRTH @ lap 11.00 : Added 0 states. 0/1 succeeded. 1/1 failed eval phase. 0/1 failed build phase.
MERGE @ lap 11.00 : 0/2 accepted. Ndiff 0.00. 0 skipped.
11.000/100 after 6 sec. | 208.1 MiB | K 9 | loss 1.175619144e-02 | Ndiff 0.050
MERGE @ lap 12.00: No promising candidates, so no attempts.
BIRTH @ lap 12.000 : None attempted. 9 past failures. 0 too small. 0 too busy.
12.000/100 after 6 sec. | 208.1 MiB | K 9 | loss 1.175618782e-02 | Ndiff 0.015
BIRTH @ lap 13.000 : None attempted. 0 past failures. 0 too small. 9 too busy.
MERGE @ lap 13.00 : 0/14 accepted. Ndiff 0.00. 0 skipped.
13.000/100 after 7 sec. | 208.1 MiB | K 9 | loss 1.175618753e-02 | Ndiff 0.004
BIRTH @ lap 14.000 : None attempted. 4 past failures. 0 too small. 5 too busy.
MERGE @ lap 14.00 : 0/6 accepted. Ndiff 0.00. 0 skipped.
14.000/100 after 7 sec. | 208.1 MiB | K 9 | loss 1.175618751e-02 | Ndiff 0.001
BIRTH @ lap 15.000 : None attempted. 3 past failures. 0 too small. 6 too busy.
MERGE @ lap 15.00 : 0/14 accepted. Ndiff 0.00. 0 skipped.
15.000/100 after 7 sec. | 208.1 MiB | K 9 | loss 1.175618751e-02 | Ndiff 0.000
BIRTH @ lap 16.000 : None attempted. 6 past failures. 0 too small. 3 too busy.
MERGE @ lap 16.00 : 0/2 accepted. Ndiff 0.00. 0 skipped.
16.000/100 after 7 sec. | 208.1 MiB | K 9 | loss 1.175618751e-02 | Ndiff 0.000
MERGE @ lap 17.00: No promising candidates, so no attempts.
BIRTH @ lap 17.000 : None attempted. 9 past failures. 0 too small. 0 too busy.
17.000/100 after 7 sec. | 208.1 MiB | K 9 | loss 1.175618751e-02 | Ndiff 0.000
BIRTH @ lap 18.000 : None attempted. 0 past failures. 0 too small. 9 too busy.
MERGE @ lap 18.00 : 0/14 accepted. Ndiff 0.00. 0 skipped.
18.000/100 after 7 sec. | 208.1 MiB | K 9 | loss 1.175618751e-02 | Ndiff 0.000
... done. converged.
Visualize clusters discovered on expanded dataset¶
show_clusters_over_time(extra_data_proposals_info_dict['task_output_path'])
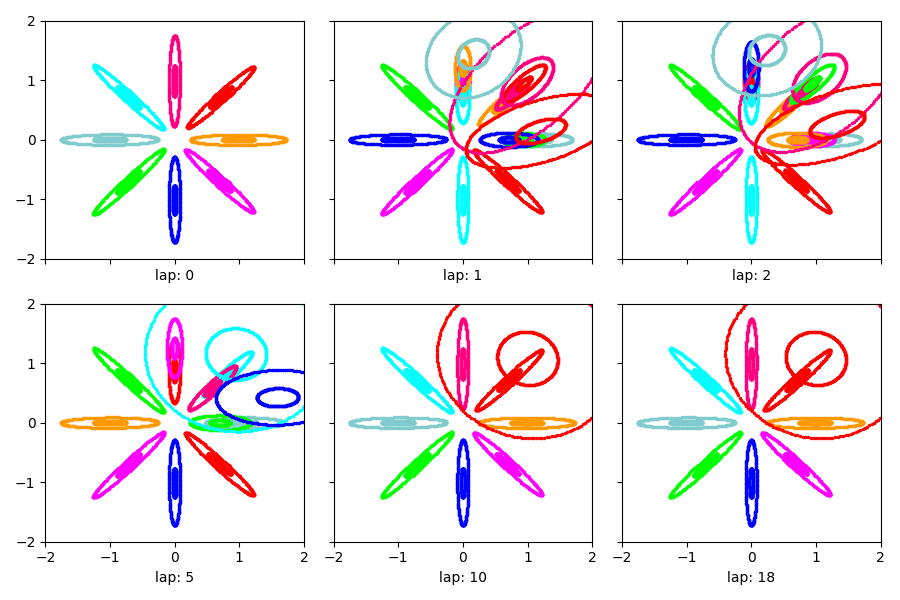
SKIPPED 3 comps with size below 0.00
SKIPPED 3 comps with size below 0.00
SKIPPED 1 comps with size below 0.00
Total running time of the script: ( 0 minutes 35.070 seconds)